Edge-Optimized LPR Pipeline for Vehicle Analytics
During my internship at meldCX, I was tasked with engineering a production-ready License Plate Recognition (LPR) pipeline. The core challenge was to move beyond high-resource laboratory models and build a system optimized for edge deployment—where real-time performance must be maintained on resource-constrained hardware.
The Challenge: Real-Time Intelligence at the Edge
In industrial and transport infrastructure environments, waiting for cloud-based inference is often not an option due to latency and bandwidth costs. My goal was to architect a vision system that could:
- Identify vehicles and plates in high-resolution video streams in real-time.
- Extract alphanumeric data with high precision under varying lighting conditions.
- Operate within the tight CPU and memory limits of edge devices.
The Technical Approach: Optimization & Communication
To solve the "Heavy Model vs. Light Hardware" problem, I engineered a multi-stage pipeline focused on efficiency:
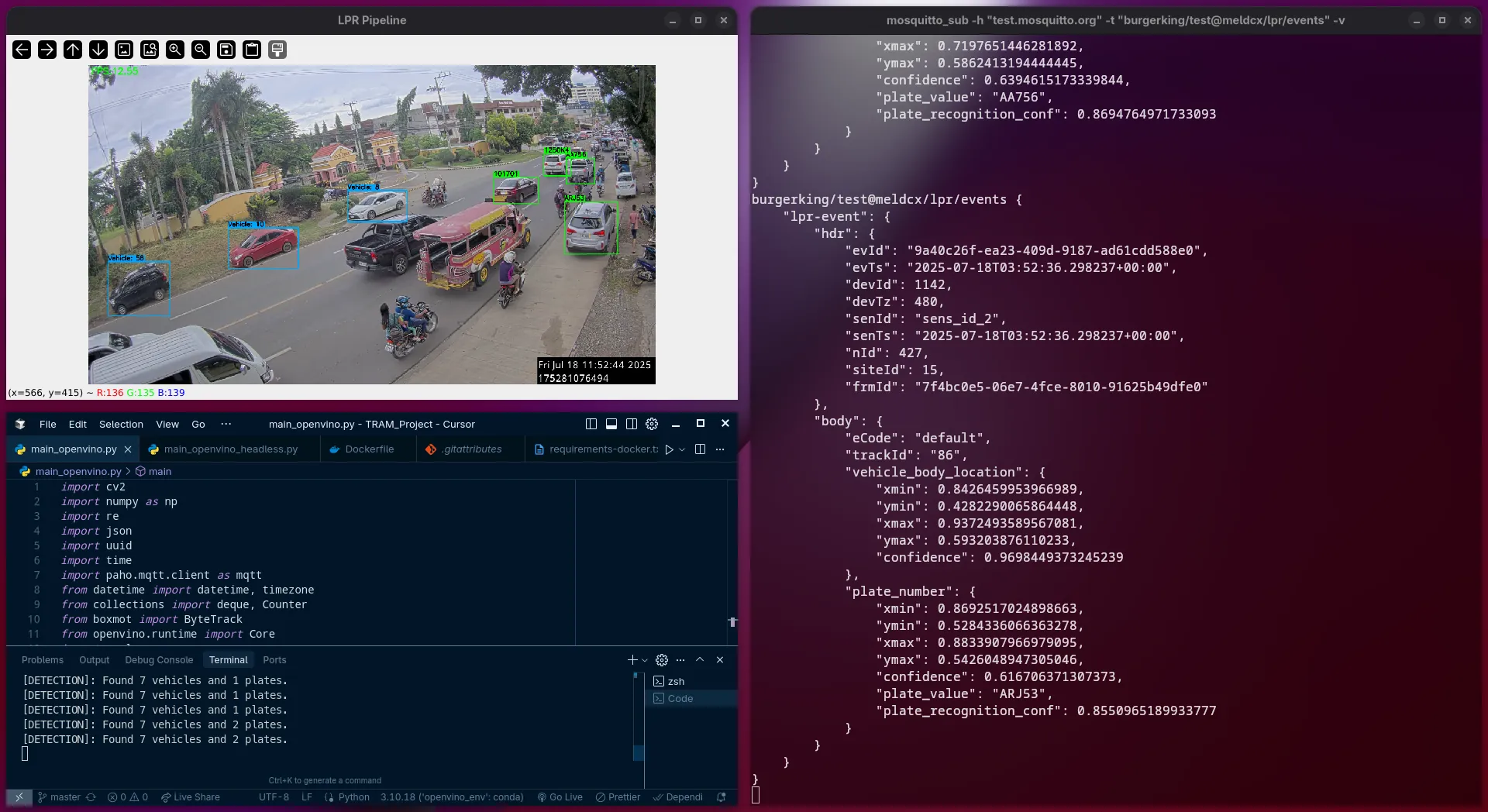
- Two-Stage Detection: I utilized fine-tuned YOLOv10s models for robust vehicle and plate detection, ensuring the system could isolate targets even in complex frames.
- High-Accuracy OCR: For text extraction, I implemented PaddleOCR (PP-OCRv5), specifically choosing the mobile-optimized version to minimize computational overhead without sacrificing character accuracy.
- Hardware Acceleration: I optimized the inference process using the Intel OpenVINO Toolkit. This allowed the models to leverage hardware-specific acceleration (CPU/VPU/GPU), significantly boosting frame rates compared to standard PyTorch backends.
- Event-Driven Communication: Instead of heavy data transfers, the system publishes recognized plate events via the MQTT protocol, enabling seamless integration with existing logistics and weight-tracking databases.
The Implementation: Dockerized Deployment
The final deliverable was a fully containerized Docker application. This ensured that the entire environment—complete with the OpenVINO runtime and PaddlePaddle backends—could be deployed consistently across various edge nodes with a single command.
The Result
The project successfully demonstrated that high-fidelity computer vision could be "shrunk" down to run on-site. By managing the end-to-end lifecycle—from fine-tuning models to containerizing the deployment—I provided a scalable solution for real-time vehicle analytics that is now CI/CD ready and optimized for the next generation of transport infrastructure.